
อปป้ามาแถลงไข เทคโนโลยี AI-OCR คืออะไร? ใช้ทำงานจุดไหนได้บ้างนะ? 🤔

‘เอาจริง มันเริ่มจากการที่สาวชาว Project Team อยากรู้ว่า ทีม DEV ใช้ AI ในการทำงานส่วนไหนบ้าง? ก็เลยไปถามเลยละกัน ให้มันเคลียร์!’
พูดคุยกับเมมเบอร์จาก Developer Team คิมลูกคิด – วิถี ภูษิตาลัย Technical Lead และ ลีจงฟลุ๊ค – ปฏิภาณ ศรีชัย Data Analyst แห่ง Punch Up และ WeVis ว่า…โดยปกติแล้ว การผลิตชิ้นงาน Data Visualization ออกมาในรูปแบบต่าง ๆ จำเป็นอย่างยิ่งที่จะต้องมีการจัดหาและปรับปรุงข้อมูลให้อยู่ในรูปแบบที่สวยงามและพร้อมใช้ก่อนเสมอ ” เรามีข้อสงสัยว่า “ในยุคที่ AI มาแรงขนาดนี้ ทีม DEV แห่ง PUxWV เนี่ย เขาใช้ AI ประยุกต์ใช้กับการทำงานส่วนไหนกันบ้างนะ?” 🤔 ถามไปถามมาเลยสนใจเรื่อง AI-OCR ซะงั้น!
แล้วเรื่องมันเป็นยังไง? มา! ไปอ่านสัมภาษณ์กันเลย 🙌
🙋♀️ AI มีส่วนช่วยในการหา DATA บ้างไหม?
👤 ลีจงฟลุ๊ค: โดยทั่วไป กรณีที่เราไม่มีข้อมูลในมือ AI ก็ช่วยได้บ้าง ในขอบเขตหรือเนื้องานที่เราไม่มีความเชี่ยวชาญ แต่สุดท้ายก็ต้องไปใช้ควบคู่กับการค้นคว้าแบบปกติ (แล้วแต่สไตล์ในการทำงาน) ส่วนตัวยังคงไบแอสกับการถาม AI โดยตรง เพราะรู้ว่าจุดอ่อนหรือข้อเสียของมันคืออะไร แต่ AI ก็มีประโยชน์ในแง่ของการถามข้อมูลในงานที่เราไม่ถนัด เช่น งานที่เกี่ยวกับคาร์บอนเครดิตหรือวิทยาศาสตร์ชีวภาพจ๋า AI จะช่วยอธิบายสิ่งที่เราไม่เข้าใจได้เหมือนกัน คิดว่า AI มีประโยชน์ในเชิงนี้มากกว่า กรณีที่มีข้อมูลอยู่แล้ว ต้องการจะคลีนข้อมูลในมือ AI ก็มีประโยชน์มากในงานที่มันซ้ำซากจำเจหรือใช้แรงมากเกิดเหตุ เช่น การทำงานกับเลขไทย เลขไทยใช้กับภาษาคอมพิวเตอร์ไม่ได้ แต่การแก้ปัญหานี้ AI ก็สามารถช่วยแปลงเลขไทยเป็นเลขอารบิกได้อย่างรวดเร็ว
มองว่า AI เก่งในงานซ้ำซากจำเจ ไม่ต้องใช้ตรรกะเยอะ เน้นใช้แรงงานซะมากกว่า
👤 คิมลูกคิด : ที่ฟลุ๊คพูดคือ AI แบบ LLM หรือ Large Language Models ซึ่งเป็น AI กระแสหลักที่คนนึกถึง มีความเชี่ยวชาญด้านภาษา ลักษณะเป็นบทสนทนาพูดคุย ถามไปในช่องแชทเพื่อแก้ไขปัญหาต่าง ๆ เช่น ChatGPT เป็นต้น ทั้งนี้ การที่มีข้อมูลอยู่แล้วในมือ เราต้องทำให้มันสวยขึ้น เอาไปใช้ได้ง่ายขึ้น ซึ่งเราสามารถใช้ AI ประเภท LLM ช่วยทำงาน ณ จุดนี้ได้ เก่งเรื่องภาษาด้วย สามารถเปลี่ยนเลขไทยเป็นเลขอาราบิค ตัดคาแรคเตอร์ที่ไม่จำเป็นออก เพราะ AI ประเภทนี้เก่งในเรื่องนี้
📌 FunFact : AI-LLM ย่อมาจาก Large Language Model หรือ โมเดลภาษาขนาดใหญ่ ซึ่งเป็นประเภทหนึ่งของปัญญาประดิษฐ์ (AI) ที่ถูกฝึกฝนบนข้อมูลข้อความจำนวนมหาศาล เพื่อให้เข้าใจ สร้างสรรค์ และประมวลผลภาษาธรรมชาติของมนุษย์ได้อย่างดี LLM เรียนรู้ความสัมพันธ์ระหว่างคำและวลีจากข้อมูลขนาดใหญ่ ทำให้สามารถคาดการณ์คำถัดไปในประโยค หรือสร้างข้อความใหม่ที่สอดคล้องกับบริบทที่ได้รับ
ตัวอย่างของ AI แบบ LLM สุดฮอตฮิต: ChatGPT, ClaudeLLaMA, BLOOM, Gemini
🙋♀️ ชิ้นงาน Punch Up และ WeVis ใช้ OCR เป็นส่วนมาก
👤 ลีจงฟลุ๊ค: งานของเราเกี่ยวข้องกับ PDF เยอะ ปัญหา คือ ไฟล์ PDF ไม่สามารถเอาไปใช้ต่อได้เลย เช่น เอกสารแสดงการโหวตของมติสมาชิกสภาผู้แทนฯ เป็น PDF ข้อมูลมีความถูกต้องแต่ก็ออกแบบให้มนุษย์อ่าน เราเลยต้องแปลงข้อมูลพวกนี้ให้อยู่รูปแบบที่คอมพิวเตอร์อ่านได้ เลยมีขั้นตอนในการ OCR ขึ้นมา อยู่ตรงกลางระหว่างกวาดหาข้อมูลและคลีนข้อมูล เพราะเรามีข้อมูลในมืออยู่ เรารู้ว่าจะทำอะไรกับข้อมูล ซึ่งส่วนนี้เทคนิค OCR ช่วยได้เยอะมาก เพราะเอกสารมีเป็นร้อย เราเลยต้องใช้เครื่องจักรมาช่วย AI-OCR เลยมาเติมเต็มตรงนี้
OCR ช่วยเปลี่ยนข้อมูลที่คอมพิวเตอร์อ่านไม่รู้เรื่องให้คอมพิวเตอร์อ่านได้ รู้เรื่อง และนำไปใช้ต่อได้อย่างมีประสิทธิภาพ
🙋♀️ แล้ว OCR คืออะไร?
👤 คิมลูกคิด: AI-OCR คือชื่อเทคนิคที่ใช้ เทคนิคกว้าง ๆ ที่คอมพิวเตอร์จะเข้าใจตัวหนังสือ ทีมเราก็ลองผิดลองถูกมาเยอะ ทั้งวิธีการและเครื่องมือที่นำมาใช้
👤 ลีจงฟลุ๊ค: ขอย้ำไว้ว่า OCR ไม่จำเป็นต้องเป็น AI เสมอไป แต่โดยไอเดีย คือ “การให้เครื่องจักรมาอ่านอักษรจากกระดาษแทนมนุษย์”
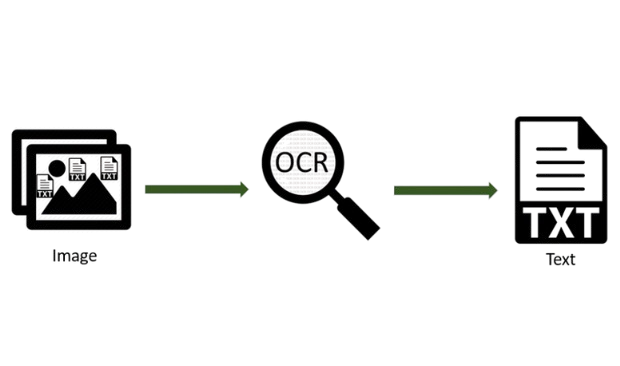
📌 OCR ย่อมาจาก Optical Character Recognition คือ เทคโนโลยีที่แปลงข้อความจากรูปภาพหรือเอกสารที่สแกน ให้กลายเป็นข้อความดิจิทัลที่สามารถแก้ไข ค้นหา และนำไปใช้งานต่อได้ ช่วยให้สามารถจัดการข้อมูลจากเอกสารต่างๆ ได้ง่ายและมีประสิทธิภาพมากขึ้น ลดความจำเป็นในการพิมพ์หรือป้อนข้อมูลด้วยตนเอง
📌 AI-OCR คือ การนำเทคโนโลยี ปัญญาประดิษฐ์ (AI) มาผสานรวมกับเทคโนโลยี OCR (Optical Character Recognition) เพื่อเพิ่มประสิทธิภาพและความแม่นยำในการแปลงข้อความจากรูปภาพหรือเอกสารสแกนให้เป็นข้อความดิจิทัล
👤 คิมลูกคิด: ส่วนมากเทคนิค OCR จะเกิดขึ้นในชิ้นงานที่เราต้องใช้เอกสารราชการไฟล์ PDF เทคนิค OCR เลยมีประโยชน์สูงสุดสำหรับองค์กรเรา เผลอๆ มากกว่า AI แบบ LLM ด้วยซ้ำ เพราะเป็นสิ่งที่เกี่ยวกับ Open Data โดยตรง ซึ่งบางชิ้นงาน ถ้าเอามนุษย์มานั่งทำกรอกข้อมูลด้วยมือ คงจะเสียเวลามากและต้องจ้างอีกกี่คนก็ไม่รู้
ตัวอย่างงานที่ใช้เทคนิค OCR
-
Parliament Watch: ขับเคลื่อนประชาธิปไตย ร่วมเฝ้าดูความเคลื่อนไหวรัฐสภา – https://wevis.info/parliamentwatch/
- Bangkok Budgeting: เปิดเผย โปร่งใส เข้าใจแผนการใช้งบ กรุงเทพมหานคร – https://bangkokbudgeting.wevis.info/

🙋♀️ AI ถึงจะช่วยลดแรง แต่ยังมีข้อบกพร่อง
👤 คิมลูกคิด: การแปลงเอกสาร PDF ให้ไปใช้ข้อมูลต่อได้ คือ งานคราฟท์ทำมือ ที่ผ่านมา ทีมเรายังไม่เจอทางออกที่สามารถแก้ไขปัญหาได้ทุกงาน ปัญหา คือ เอกสารของแต่ละโปรเจกต์แตกต่างกัน เอกสารลงมติจากรัฐสภา ราชกิจจาหรือเอกสารงบประมาณมีรูปแบบที่แตกต่างกัน ต่อให้เราจะแชร์เครื่องมือแต่ก็ไม่ได้การันตีว่าจะสามารถใช้ซ้ำได้ในทุกงาน
คอมพิวเตอร์ไม่ได้ 100% ต่อให้ใช้กระบวนการหรือเครื่องมือที่ดีที่สุดแล้ว แต่ก็จะเกิดความผิดพลาดบางอย่างได้
👤 ลีจงฟลุ๊ค: หากไม่ใช้ OCR วิธีการดั้งเดิม คือ การหาคนมานั่งกรอกข้อมูล เราจึงจำเป็นที่จะต้องมอง OCR ในฐานะผู้ช่วย (Assist) มองมันในฐานะเครื่องมือที่ช่วยประหยัดเวลาและทรัพยากรมนุษย์ เพราะท้ายที่สุดแล้ว เราก็ต้องให้คนในทีมหรือมนุษย์มาตรวจสอบผลลัพธ์อีกที
👤 คิมลูกคิด: คนยังต้องทำงานร่วมกับ OCR ตอนนี้ไม่มีโปรเจกต์ไหนที่ออกจากคอมพิวเตอร์แล้วเราเชื่อมัน 100% ต้องมีมนุษย์มาตรวจสอบความผิดพลาดอีกรอบเสมอ
🙋♀️ มี AI-OCR แนะนำไหม
👤 ลีจงฟลุ๊ค: ข้อดีของ AI ยุคนี้ คือ มันแมสมากเสียจนไม่ว่าคุณจะเป็นใครก็สามารถเข้าถึงได้
👤 คิมลูกคิด: เราอยู่ในยุคที่เครื่องมือ OCR ออกใหม่ทุกเดือน เทคโนโลยีมันไปไว แต่ก็ยกตัวอย่างได้อยู่ จัดไป 👇🏼
ตัวอย่างเครื่องมือ AI-OCR ที่ใช้ทำงานในช่วงนี้
-
- ลีจงฟลุ๊คแนะนำ Easy OCR – ใช้งาน Data ทั่วไป
- คิมลูกคิดแนะนำ Tesseract – มีความ School หน่อย ๆ ค่อนข้างป๊อปและใช้ง่าย
บางกรณี มีการใช้ AI ในรูปแบบของ LLM มา OCR บ้าง แต่ยังมีข้อจำกัดด้านความสามารถและลักษณะของงาน
🙋♀️ ที่ต้อง OCR ก็เพราะปัญหาข้อมูลเปิดแบบไทย ๆ
👤 ลีจงฟลุ๊ค: ผู้ถือข้อมูล (โดยส่วนมากคือรัฐ) มักไม่มีช่องทางหรือเลือกที่จะไม่เผยแพร่ข้อมูลให้กับสาธารณะ เทคโนโลยี OCR เลยมาตอบโจทย์ ณ จุดนี้ พอมามองในเชิงสังคม เทคโนโลยี OCR มีส่วนช่วยให้ผู้คนเข้าถึงข้อมูลในรูปแบบดิจิตัลมากขึ้น
ถ้ารัฐเปิดข้อมูลที่คอมพิวเตอร์อ่านมาได้ตั้งแต่แรกจะประหยัดเวลาไปเยอะมาก
👤 คิมลูกคิด: มันจะประหยัดเวลาไปเยอะมาก ถ้าได้ข้อมูลที่สวยมาแล้ว ลดเวลาการทำงานไปได้ถึงครึ่งนึง เราเสียเวลาไปเยอะมากจากการแปลงข้อมูลรูปแบบที่ยากให้ใช้ง่ายขึ้น สิ่งนึงที่น่าสนใจ คือ เราได้มีโอกาสไปหาข้อมูลในเอกสารเก่า (เก่าจริง ๆ เป็นแบบพิมพ์ดีด) ซึ่งเข้าใจได้ในจุดนี้ แต่เมื่อข้อมูลมันใหม่ขึ้นเรื่อย ๆ เอกสารราชการก็ยังเป็นรูปแบบ PDF อยู่ดี ทั้งที่ตอนนี้มีข้อเสนอแนะของสำนักงานพัฒนารัฐบาลดิจิทัล (องค์การมหาชน) – DGA ที่ปรากฎข้อมูลในรายงานว่า “หน่วยงานรัฐต้องเปิดทำ Open DATA อย่างไร” นี่คือสิ่งที่สื่อว่า…..ประเทศเรามีแนวทาง (Guideline) แล้ว ว่าจะต้องทำข้อมูลเปิดยังไง แต่ปัญหา คือ มันไม่ถูกบังคับใช้หรือถูกดันให้กลายเป็นกฎหมาย หน่วยงานรัฐจึงไม่จำเป็นต้องทำและไม่มีบทลงโทษด้วยหากไม่ทำ
ประเทศไทยมีองค์ความรู้สำหรับ Open Data แล้ว แต่ไม่มีการบังคับใช้ ไม่มีทั้งแรงจูงใจและบทลงโทษ
👤 ลีจงฟลุ๊ค: พูดถึง Open Data กับรัฐ จริง ๆ ไม่ได้โฟกัสแค่เรื่อง OCR นะ ก่อนหน้านี้ ทีมไต้หวันมีการใช้ AI แปลงเสียงในรัฐสภาไปเป็นดิจิตัล ในกรณีไทยเรายังมีปัญหาที่ว่าการอภิปรายในรัฐสภาหรือรัฐไทยไม่ได้เปิดเผยไปซะหมด ข้อมูลไม่ได้เข้าถึงง่ายหรือเอาไปใช้ต่อได้ง่ายขนาดนั้น ในบริบทไทย ภาคประชาสังคมจึงต้องใช้ AI มาช่วยแปลงข้อมูลนอกจากนี้ ไทยยังใช้เอกสารแบบ PDF อยู่เป็นส่วนมาก OCR เลยมีบทบาทมาก ๆ
👤 คิมลูกคิด: บริบทไทย คือ รัฐเปิดข้อมูลบางอย่างที่มักจะนำไปใช้ต่อได้ยาก ภาคประชาสังคมเลยต้องใช้เครื่องมือทางเทคโนโลยี ซึ่ง AI ก็เป็นหนึ่งในนั้น เพื่อให้ข้อมูลมีลักษณะรูปแบบที่ใช้ง่ายขึ้น
🙋♀️ สุดท้ายนี้ ในฐานะ DEV อยากฝากอะไรทิ้งท้ายชาวเน็ตบ้าง?
👤 คิมลูกคิด: ข้อมูลควรถูกเปิดมาอย่างดีตั้งแต่ต้นทาง ซึ่งคอนเซ็ปหลัก ๆ ของ Open Data คือ…
- สร้างความน่าเชื่อถือ
- ชุดข้อมูลที่ทำให้คนนำไปพัฒนาเป็นสิ่งที่สามารถแก้ไขปัญหาสังคมได้ต่อ
ถ้ามีการเปิดข้อมูลมาอย่างดีตั้งแต่ต้น ข้อมูลจะกลายเป็นทรัพยากรสำคัญที่ทำให้ผู้คนสามารถนำไปใช้ต่อ มีส่วนร่วมในการพัฒนาประเทศได้ ในมุมของ AI เรารู้สึกว่าการแก้ไขปัญหาโดยใช้เทคโนโลยีจะสามารถช่วยเหลืองานภาครัฐได้อย่างดี ให้คำนึงว่า…..
เทคโนโลยีเรามีแล้ว แต่กฎระเบียบและหลักเกณฑ์ต้องปรับตามไปด้วย นี่คือความท้าทายหลักของรัฐไทย
👤 ลีจงฟลุ๊ค: อยากฝากในมุมที่ว่า…ไม่อยากให้มองแค่ว่า AI-OCR คือ การแปลงข้อมูลเก่าให้ปรับเปลี่ยนมาใช้ได้นั้น ไม่ใช่แค่เราที่ใช้ได้ แต่รัฐก็ใช้ได้ ตัดภาพมาจากมุมประชาชนที่ทำงานเกี่ยวกับข้อมูลที่อ่านยาก ทั้งที่เรามีทรัพยากรที่จำกัด แต่เราก็ยังสามารถแปลงข้อมูลออกมาเป็นดิจิตัลให้สามารถทำงานต่อได้ ฉะนั้นแล้ว
ถ้ารัฐพร้อมที่จะเปิดเผยและปรับเปลี่ยนเทคโนโลยี รัฐมีทรัพยากรมากพอที่จะนำเทคโนโลยีเหล่านี้มาปรับใช้ในการทำงานกับข้อมูลได้ง่ายมากกว่าประชาชนเยอะ ขอแค่รัฐพร้อมที่จะเปิด



